Abstract
Large language models show promising capabilities for contextual fact-checking on social media: they can verify contested claims through deep research, synthesize evidence from multiple sources, and draft explanations at scale. However, prior work evaluates LLM fact-checking only in controlled settings using benchmarks or crowdworker judgments, leaving open how these systems perform in authentic platform environments. We present the first field evaluation of LLM-based fact-checking deployed on a live social media platform, testing performance directly through X Community Notes' AI writer feature over a three-month period. Our LLM writer, a multi-step pipeline that handles multimodal content (text, images, and videos), conducts web and platform-native search, and writes contextual notes, was deployed to write 1,614 notes on 1,597 tweets and compared against 1,332 human-written notes on the same tweets using 108,169 ratings from 42,521 raters. Direct comparison of note-level platform outcomes can be complicated by differences in submission timing and rating exposure between LLM and human notes; we therefore pursue two complementary strategies: a rating-level analysis modeling individual rater evaluations, and a note-level analysis that equalizes rater exposure across note types. Rating-level analysis shows that LLM notes receive more positive ratings than human notes across raters with different political viewpoints, suggesting potential for LLM-written notes to achieve cross-partisan consensus. Note-level analysis confirms this advantage: among raters who evaluated all notes on the same post, LLM notes achieve significantly higher helpfulness scores. Our findings demonstrate that LLMs can contribute high-quality, broadly helpful fact-checking at scale, while highlighting that real-world evaluation requires careful attention to platform dynamics absent from controlled settings.
LLM Writer Pipeline
Our AI writer pipeline processes posts eligible for an AI note through a multi-step workflow. For each post, the system retrieves the full post context, conducts research with web and X search, decides whether a note is needed, drafts a Community Note grounded in research evidence, verifies all source URLs, and submits the final note to the platform.
Key Points
Ecological Validity
We present, to our knowledge, the first online evaluation of AI fact-checking deployed on a real-world social media platform, assessed using organic user feedback under natural conditions, rather than recruited evaluators or synthetic benchmarks.
Platform Dynamics Complicate Real-world Evaluation
LLM notes were typically submitted later than human notes (because platform policy requires users flag posts first before AI writers can write) and accumulated fewer ratings (median 22 vs. 51), resulting in different exposures. Since the Community Notes scoring algorithm penalizes notes with fewer ratings, platform-generated helpfulness scores could unfairly disadvantage LLM notes. We address this with two complementary analyses: one that examines individual raters' evaluations directly, and one that ensures LLM and human notes are compared under equal exposures before computing helpfulness scores.
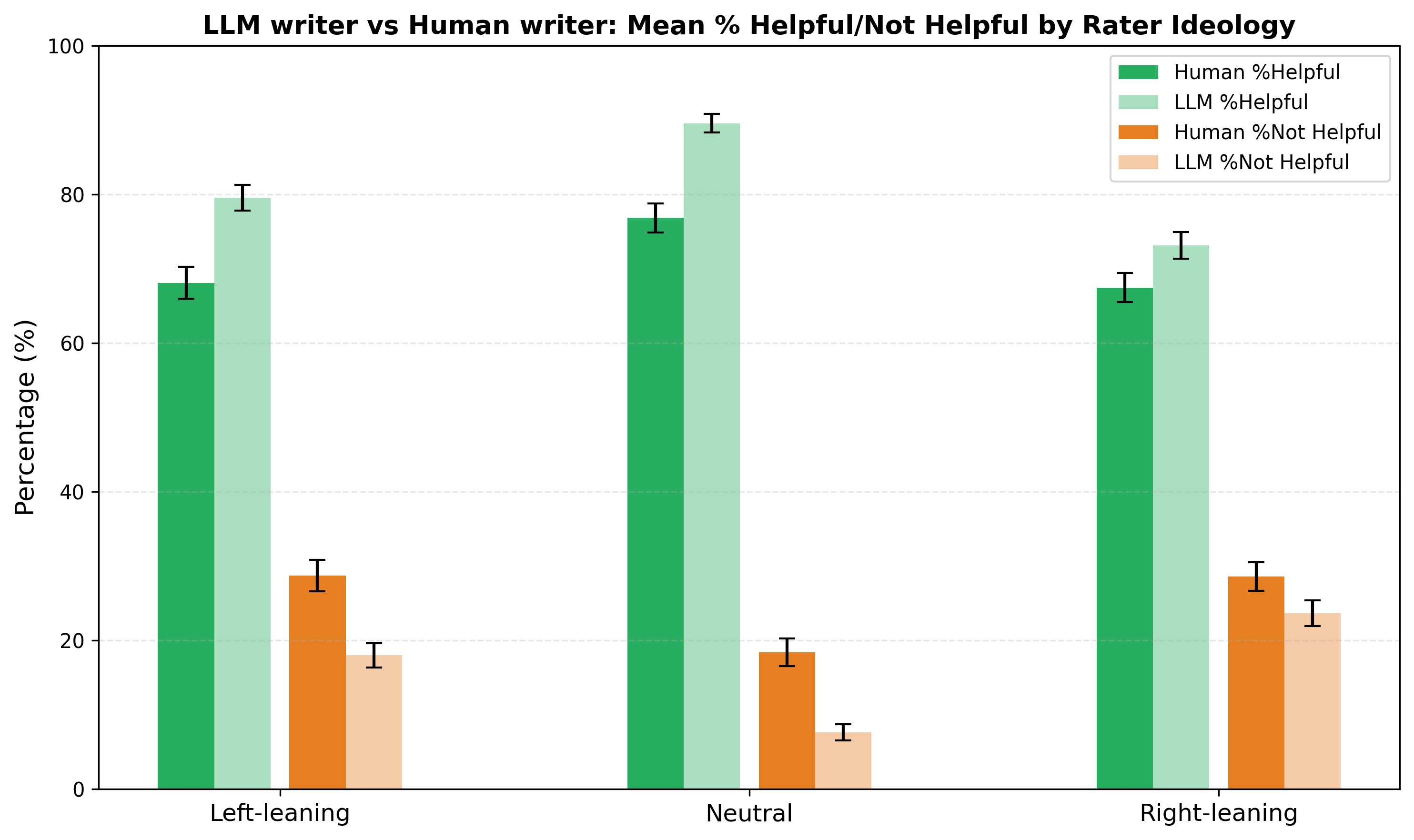
LLM Notes Receive More Positive Ratings Across the Ideological Spectrum
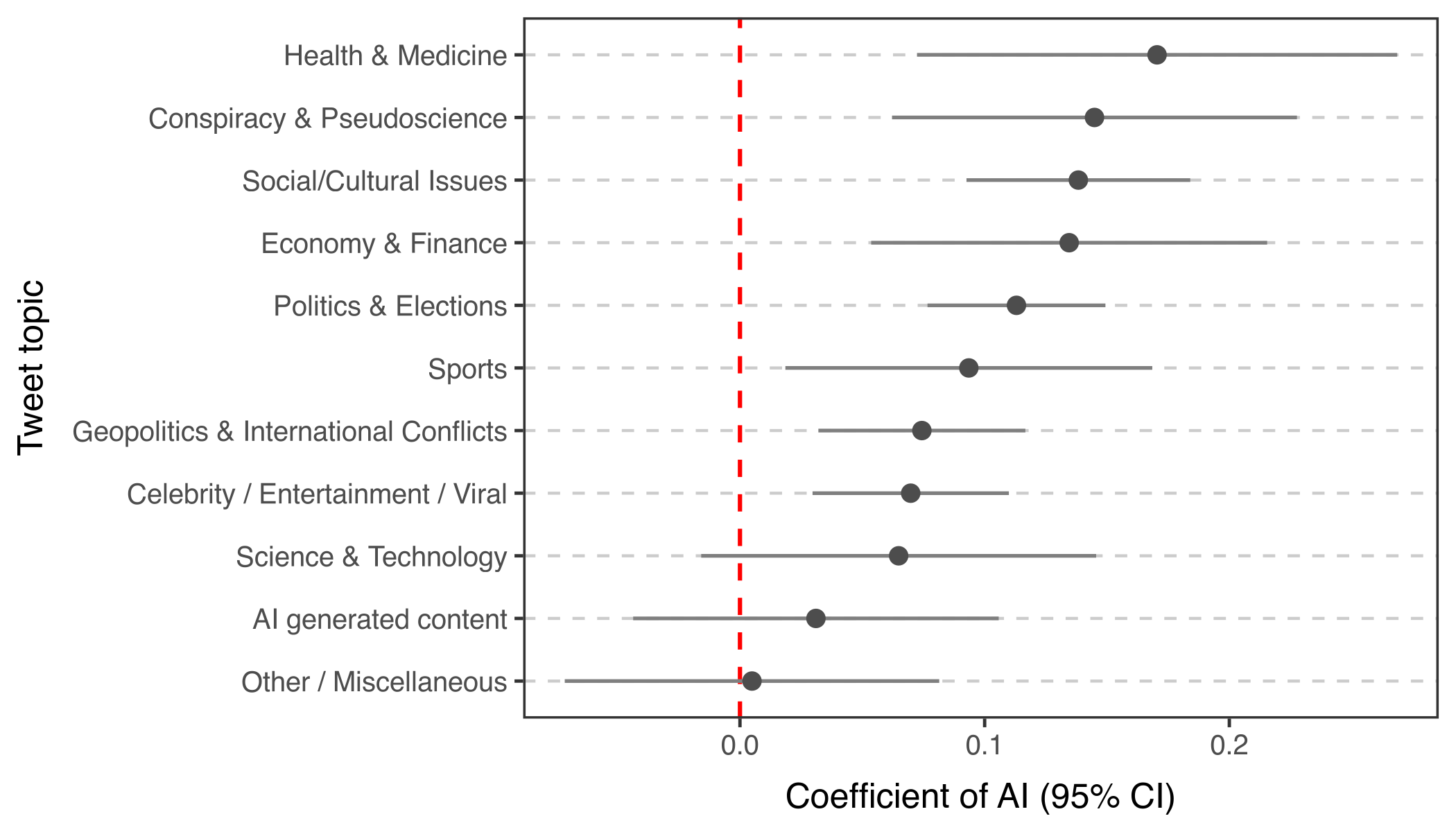
Across raters of different political leanings — left, neutral, and right — LLM-written notes had higher avg. %helpful ratings and lower avg. %unhelpful ratings than human-written notes, with the largest advantage among politically neutral raters (Figure 1). A linear mixed effects model controlling for raters' political ideology estimates a 10 percentage point increase in the probability of a note being rated helpful for LLM notes among centrist raters. This advantage also varies by topic: it is largest for health and medicine and conspiracy/pseudoscience and smallest for posts about AI-generated content (Figure 2).
Equal-Exposure Note-Level Analysis Confirms LLM Advantage
We equalized exposure by restricting to raters who evaluated every note on a given tweet, and then recomputed the note helpfulness scores with only ratings from these raters. While platform-generated helpfulness scores show no significant difference between LLM and human notes (0.25 vs. 0.24, linear mixed-effects model p = 0.253), under equal exposure, LLM notes achieved significantly higher helpfulness scores than human notes (0.21 vs. 0.18, linear mixed-effects model adj. p = 0.010).
Citation
@misc{li2026aifactcheckingwildfield,
title={AI Fact-Checking in the Wild: A Field Evaluation of LLM-Written Community Notes on X},
author={Haiwen Li and Michiel A. Bakker},
year={2026},
eprint={2604.02592},
archivePrefix={arXiv},
primaryClass={cs.CY},
url={https://arxiv.org/abs/2604.02592},
}
Build Your AI Community Notes Writer
Designing AI fact-checking systems that work in the real world is both super fun and deeply meaningful. X's Community Notes offers a unique opportunity to build and test these systems at scale, with real users interacting with your AI writer.
It is super cool that X Community Notes provides a public AI writer API that lets everybody build their own automated fact-checking pipeline and run on Community Notes. They also make their data and algorithm publicly available.
Questions or Feedback?
We are curious about your thoughts on this work. Leave your message below and it will be sent us.